
Email: ananyea [at] andrew [dot] cmu [dot] edu
I am a founding research scientist at Skild AI and a PhD student at Carnegie Mellon University working with Deepak Pathak. I am interested in building general-purpose, omni-bodied robot brains that work across tasks, environments, and robots.
I graduated from IIT Delhi with a B.Tech. in Computer Science and a President's Gold Medal (equivalent to valedictorian). In the past, I have been lucky to work with Prof. Mausam on neuro-symbolic AI and with Prof. Manik Varma on Extreme Classification. I have also had the good fortune of interning at Microsoft Research India where I worked with Dr. Ankit Garg on algebraic complexity. I also have a gold medal in the International Physics Olympiad (IPhO) in 2017.
Publications
Jayesh Singla*, Ananye Agarwal*, Deepak Pathak
ICML 2024 (Oral)
webpageShagun Uppal, Ananye Agarwal, Haoyu Xiong, Kenneth Shaw, Deepak Pathak
CVPR 2024
webpage | arXivAnanye Agarwal, Shagun Uppal, Kenneth Shaw, Deepak Pathak
CoRL 2023
webpage | arXivXuxin Cheng*, Kexin Shi*, Ananye Agarwal, Deepak Pathak
ICRA 2024
webpage | arXiv | codeKenneth Shaw, Ananye Agarwal, Deepak Pathak
RSS 2023
webpage | paperAnanye Agarwal*, Ashish Kumar*, Jitendra Malik†, Deepak Pathak†
CoRL 2022 (Best Systems Paper Award)
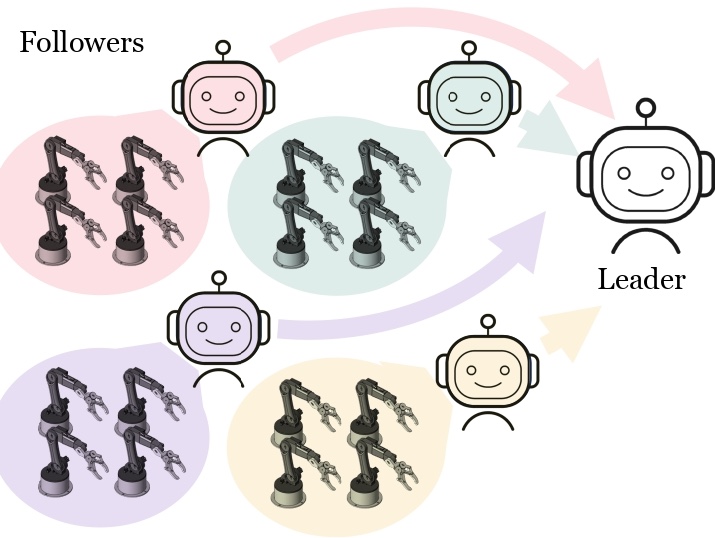
webpage | arXiv | demo | in the media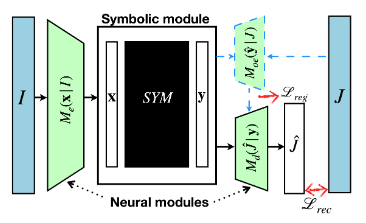
Ananye Agarwal, Pradeep Shenoy, Mausam
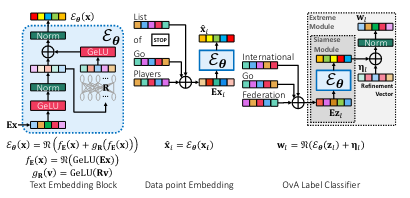
K. Dahiya, A. Agarwal, D. Saini, K. Gururaj, J. Jiao, A. Singh, S. Agarwal, P. Kar and M. Varma
ICML 2021
PDF | codeLive Demos
Our small low-cost robot can perceive and traverse challenging terrain. This uses a single neural network running onboard that directly maps pixels to joint torques.
Press Coverage








Blog
Beyond Teleoperation: Scaling Robot Intelligence via Observational Learning
In the race to build truly general-purpose robotics, the industry has hit a familiar wall: the data bottleneck. While Large Language Models (LLMs) flourished by scraping the vast expanse of the internet, robotics has struggled to find its "Common Crawl." The prevailing strategy has been to scale teleoperation—human operators manually guiding robots to collect precise motor-torque sequences.
However, at Skild AI, we believe teleoperation alone cannot bridge the gap to foundation-model scale. It faces two fatal challenges:
- Diversity: Teleoperation is tethered to physical presence. Most data is trapped in sterile labs or specific environments where a robot is already deployed, missing the messy, infinite variety of the real world.
- Scale: Teleoperation happens in real-time. Even if we mobilized a global workforce to "drive" robots 24/7, the time required to reach the trillions of tokens equivalent to an LLM is mathematically unfeasible.
Learning by Watching
If we look at biological intelligence, the solution is hiding in plain sight. Humans don't learn to make tea by being told the exact Newton-meters of force to apply to a kettle. We learn through observational learning. We possess a foundation of kinematics and dynamics that allows us to watch a visual demonstration, internalize the intent, and map those actions onto our own bodies. This data—human video—is already abundant. From first-person "egocentric" headcam footage to the millions of instructional videos on YouTube, the "internet-scale" dataset for robotics already exists. It just isn't "robot-native."
The Embodiment Gap
The reason the industry hasn't shifted entirely to video data is that it's technically daunting. Unlike text, video data for robotics suffers from:
- Missing Signals: Videos don't show the underlying forces, torques, or tactile feedback.
- The Embodiment Gap: A human hand, a 7-DOF industrial arm, and a quadruped all have vastly different morphologies. Mapping a human's "grasp" to a robot's "actuation" is a massive translation problem.
The Skild AI Solution: Omni-bodied Learning
Bridging embodiment is a core capability of our model, enabling new skills to be learned directly from video demonstrations. We finetune our model to perform new skills by watching videos alone, and only a small amount of robot data (<1 hr). We believe this fundamentally changes the robotics data bottleneck, making scalable task learning for foundation models feasible.